Building an Agentic-SRE: Future of Incident Response¶
In Site Reliability Engineering (SRE), every second counts. When an alert fires, its a race to identify the root cause and implement a fix. This process is often a manual, time-consuming journey through logs, metrics, and documentation.
In this article I outline an SRE agent that can plan, reflect, identify root causes, and recommend remediation when an alert arrives. While the ultimate goal is a fully reactive system, the initial objective is to significantly reduce the search space that a human engineer needs to navigate.
I demonstrate a proof-of-concept orchestrator agent I've been building that will be expanded to form the main core of an agentic SRE, https://github.com/DonTron-prog/agent_sre.git. The orchestrator chooses a tool (RAG, search, deep-research, and calculator) that is based off the awesome Atomic-Agents framework.
How it Works: An Overview¶
At its core, the Agentic-SRE is an intelligent system designed to mimic the troubleshooting process of a seasoned engineer. Upon receiving an alert, it embarks on a structured investigation, leveraging a suite of powerful tools and techniques.(Pienaar et. al.)[https://cleric.ai/blog/what-is-an-ai-sre]
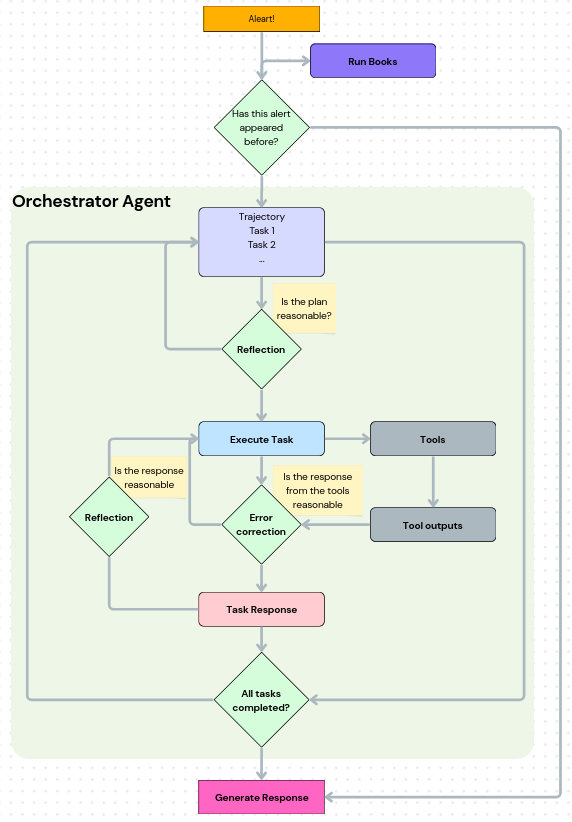 Operational workflow of the Agentic SRE, showing how it processes alerts through a structured decision-making pipeline that includes trajectory planning, reflection-based reasoning, and orchestration of task execution and tool integration, before generating final responses.
Operational workflow of the Agentic SRE, showing how it processes alerts through a structured decision-making pipeline that includes trajectory planning, reflection-based reasoning, and orchestration of task execution and tool integration, before generating final responses.
The process can be visualized in two key stages: the high-level orchestration of tools and the iterative reasoning loop.
First, the Orchestrator Agent acts as the central coordinator. When an alert comes in, it analyzes the context and decides which tool is best suited for the initial investigation. This could be a quick search of internal knowledge bases or a more complex deep research query.
Once a plan is formed, the agent enters a ReAct (Reasoning and Acting) loopYao el al. 2022. It executes a task, reflects on the output, and refines its approach. This iterative process of execution, reflection, and error correction allows the agent to intelligently navigate the problem space until a satisfactory solution is found.
The Starting Point: Alerts¶
An alert set the process in motion. These can come from various monitoring services like Datadog, Prometheus, or via webhooks. To be useful, these alerts are normalized into a structured format, typically a JSON object, containing key information:
example_alerts = [
{
"alert": "Critical failure: 'ExtPluginReplicationError: Code 7749 - Sync Timeout with AlphaNode' in 'experimental-geo-sync-plugin v0.1.2'",
"context": "System: Primary PostgreSQL Database. Plugin: experimental third-party plugin integrated yesterday. Internal Documentation: NO internal docs exist for this plugin."
},
{
"alert": "Pod CrashLoopBackOff for 'checkout-service'. Error: 'java.lang.OutOfMemoryError: Java heap space'",
"context": "System: Kubernetes microservice (Java Spring Boot). Traffic: 3x normal load due to flash sale."
},
{
"alert": "API endpoint /api/v2/orders returning 503 Service Unavailable for 5% of requests. Latency P99 is 2500ms.",
"context": "Current error rate threshold: < 1%. Latency SLO: P99 < 800ms."
}
]
The more system information that can be added to the alert is better (such as time, origin or type). The alert and context form the basis of our queries for gathering more context.
The Power of Memory: Learning from Past Incidents¶
Recurring issues can often be resolved more quickly if the resolution was documented. One of the first things the Agentic-SRE should do is check its memory for similar past incidents. If a new alert matches a previously resolved one, the agent can immediately suggest the documented fix and associated Runbook. This addresses a common scenario where on-call engineers may not be aware of prior resolutions for repeat incidents.
In this implementation, we, naturally, have the internal memory of the LLMs, and have focused on a short-term, conversational memory system that:
- Manages the chat history for the AI agents,
- Maintains a coherent conversational flow,
- Has a configurable message limit to manage memory usage.
This memory is key to the agent's ability to understand the problem and iterate on its plan by retaining the context of previous steps. It will be built upon to include long-term memory connected to RAG to store user or engineer info and preferences, significant events or findings, and record postmortems.Bae et al
Planning: Charting a Course to Resolution¶
For new and complex alerts, a plan is essential. The agent must break down the high-level task of "find the root cause" into a series of smaller, manageable steps. This planning is hierarchical. A planner agent devises the overall strategy, while the orchestrator executes the individual tasks.
Planning is inherently a path-finding problem. The agent must choose the most promising path from various options and tools. As it gathers more information with each step, it can prune unproductive paths and learn necessary parameters, zeroing in on the solution.
To aid in this process, the planner must have the necessary context of the system. For example a knowledge graph provides a high-level, up-to-date view of the system's architecture. This graph, which can be deterministically built and using tools like kubectl and injected into the planners context. The graph represents the interconnected components of the platform, from regions and projects down to individual containers and processes and helps in isolating the root cause.Hao et al
Example of Distributed cloud infrastrucrture¶
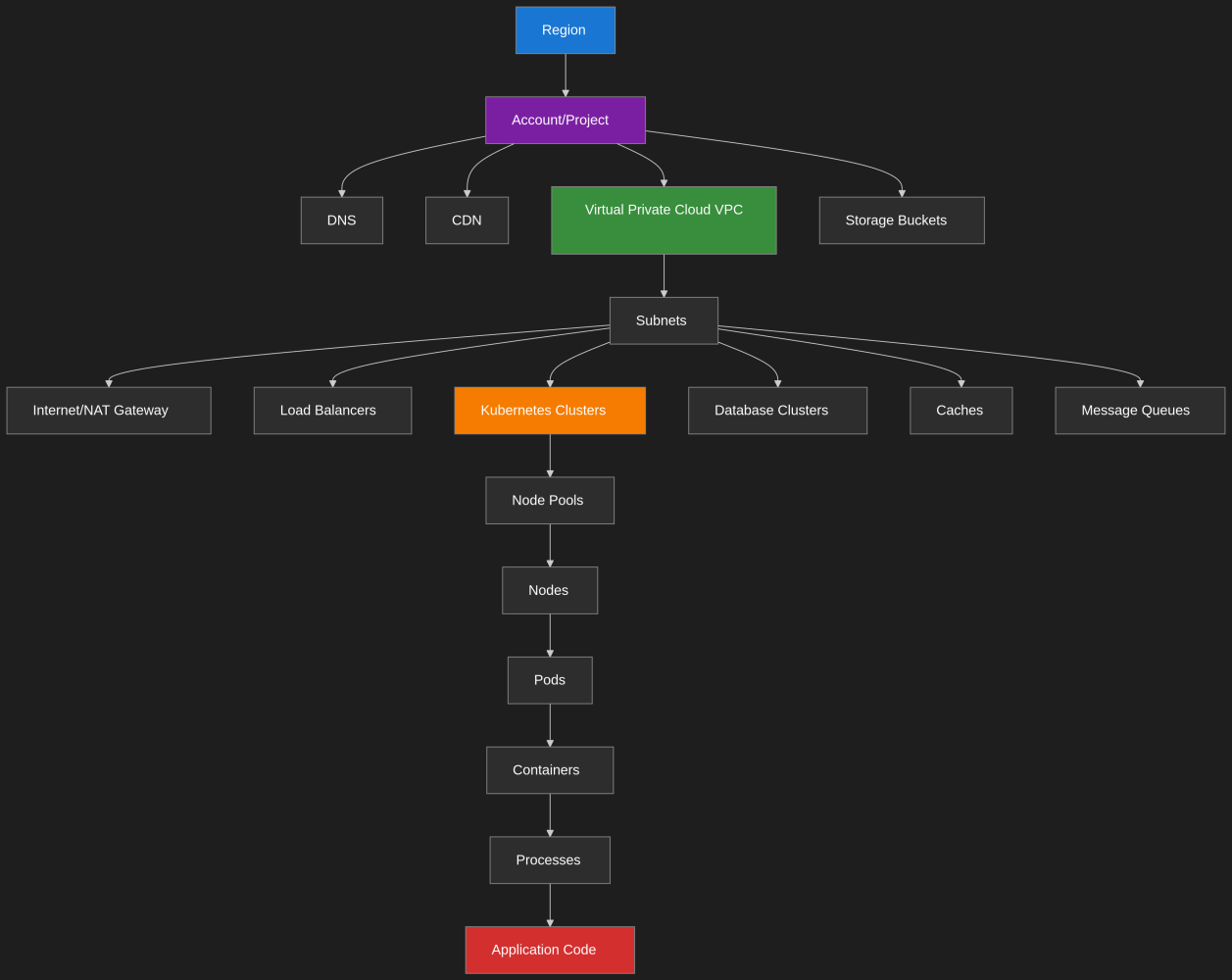 hierarchical structure of modern cloud infrastructure, showing how applications flow from regional cloud boundaries down through networking layers to containerized workloads running application code. The architecture demonstrates the nested relationship between cloud services, from high-level account organization to the granular execution environment where business logic operates.
hierarchical structure of modern cloud infrastructure, showing how applications flow from regional cloud boundaries down through networking layers to containerized workloads running application code. The architecture demonstrates the nested relationship between cloud services, from high-level account organization to the granular execution environment where business logic operates.
Built on Atomic Agents: A Developer-First Framework¶
The Agentic-SRE described bellow is built using Atomic Agents, which is an approach to AI agent development that prioritizes developer control and maintainability. It was easy to build upon the prebuilt tools and examples to suit this task.
Unlike frameworks that bury you in abstractions, Atomic Agents follows a simple Input-Process-Output (IPO) model. Every agent and tool has:
- Input Schema (via Pydantic) - exactly what data goes in
- Processing Function - the actual logic
- Output Schema - precisely what comes out
This means no guesswork about data shapes, no debugging nightmares through layers of abstraction, and no black-box orchestrators making decisions for you.
# Clean, predictable agent definition
agent = BaseAgent(
BaseAgentConfig(
client=instructor.from_openai(openai.OpenAI()),
model="gpt-4o-mini",
input_schema=OrchestratorInputSchema,
output_schema=OrchestratorOutputSchema,
system_prompt_generator=system_prompt_generator
)
)
What makes Atomic Agents particularly powerful for SRE use cases: - Modularity: Each tool (RAG, web search, calculator) is an independent "atom" that can be swapped, tested, or debugged in isolation. - Schema Chaining: Tools connect seamlessly when their input/output schemas align - no manual data transformation needed. - Debuggability: Set breakpoints anywhere. See exactly what's in your system prompt, input data, or output JSON. - Performance: scale it like any traditional backend using python with standard deployment patterns.
The framework's philosophy of "doing one thing well" aligns perfectly with SRE principles. After getting lost in LangGraph and and CrewAI I found it an ideal foundation for the Agentic-SRE.
Orchestration: The Intelligent Coordinator¶
The orchestrator is the heart of our Agentic-SRE. It's an intelligent decision-making coordinator that analyzes incoming requests and routes them to the most appropriate tool. To try it out follow the setup in the README then run:
python orchestration_agent/orchestrator.py
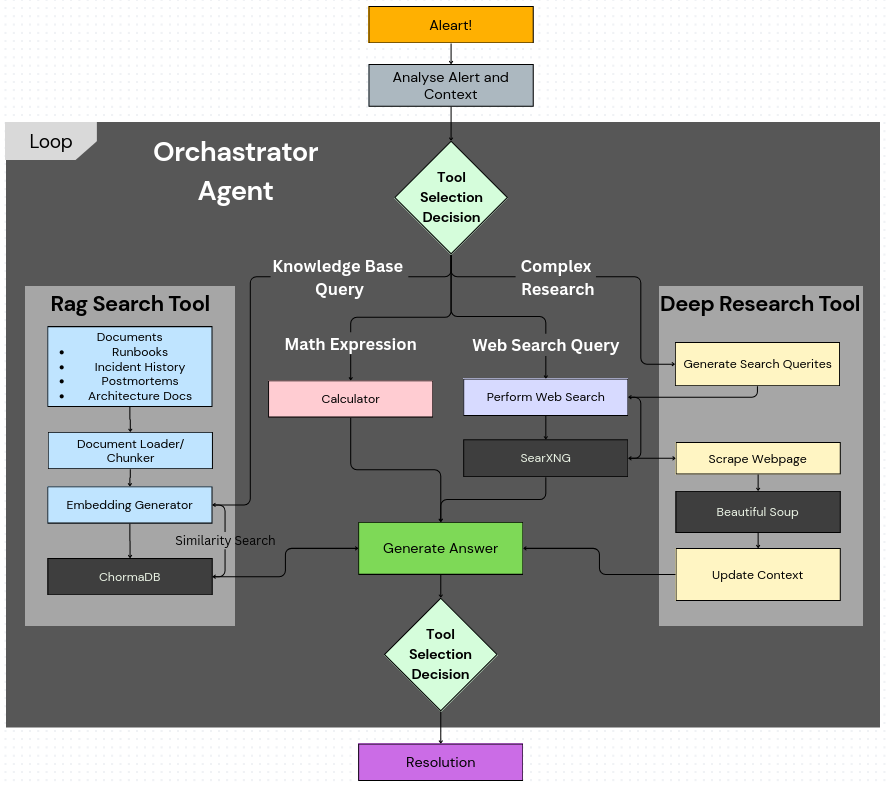
Orchestrator Agent architecture that intelligently routes alerts through specialized tools - using Calulator, Web-Search, RAG Search for knowledge base queries against documents and incident history, and Deep Research for complex web-based investigations - before generating comprehensive resolutions through an iterative decision-making process.
It follows a simple yet powerful pattern: analyze, decide, and route.
- Analyze the context: It examines the input (alerts, error messages, user queries) along with any relevant contextual information.
- Make intelligent decisions: It uses LLM reasoning to determine which specialized tool will provide the most valuable information.
- Routes and executes: It directs the request to the chosen tool with the correctly formatted parameters.
- Repeats as needed: This loop continues as the agent gathers more information.
def execute_tool(searxng_tool, calculator_tool, rag_tool, deep_research_tool, orchestrator_output):
"""Route to the appropriate tool based on orchestrator decision."""
if orchestrator_output.tool in ("search", "web-search"):
if not isinstance(orchestrator_output.tool_parameters, SearxNGSearchToolInputSchema):
raise ValueError(f"Invalid parameters for search tool")
return searxng_tool.run(orchestrator_output.tool_parameters)
elif orchestrator_output.tool == "rag":
if not isinstance(orchestrator_output.tool_parameters, RAGSearchToolInputSchema):
raise ValueError(f"Invalid parameters for RAG tool")
return rag_tool.run(orchestrator_output.tool_parameters)
elif orchestrator_output.tool == "deep-research":
return deep_research_tool.run(orchestrator_output.tool_parameters)
elif orchestrator_output.tool == "calculator":
return calculator_tool.run(orchestrator_output.tool_parameters)
else:
raise ValueError(f"Unknown tool: {orchestrator_output.tool}")
In my implementation, the Agentic-SRE uses the following tools:
- RAG (Retrieval-Augmented Generation): For querying internal knowledge bases, runbooks, and documentation.
- Web Search: For finding external information like error codes, CVEs, or troubleshooting guides. For this, I used SearxNG, a privacy-respecting metasearch engine.
- Deep Research: For comprehensive, multi-source analysis of complex problems.
- Calculator: For metric calculations, threshold analysis, and numerical computations.
To ensure reliability, Atomic-Agents uses Pydantic for validating inputs and outputs and Instructor to work with structured outputs from LLMs, which simplifies managing validation, retries, and streaming responses.
Instructor Setup¶
# Setup structured LLM client
client = instructor.from_openai(openai.OpenAI(api_key=config["openai_api_key"]))
# Agent automatically validates and retries based on Pydantic schemas
agent = BaseAgent(
BaseAgentConfig(
client=client,
...
)
)
Pydantic validations¶
class OrchestratorInputSchema(BaseIOSchema):
"""Input schema for the SRE Orchestrator Agent."""
system_alert: str = Field(..., description="The system alert received (e.g., 'High CPU utilization on server X').")
system_context: str = Field(..., description="Contextual information about the system (e.g., 'Production web server, recent deployment v1.2').")
class OrchestratorOutputSchema(BaseIOSchema):
"""Output schema containing the tool to use and its parameters."""
tool: str = Field(..., description="The tool to use: 'search', 'calculator', 'rag', or 'deep-research'")
tool_parameters: Union[SearxNGSearchToolInputSchema, CalculatorToolInputSchema, RAGSearchToolInputSchema, DeepResearchToolInputSchema] = Field(
..., description="The parameters for the selected tool"
)
Tools¶
Internal Knowledge: Retrieval-Augmented Generation (RAG)¶
When an alert isn't immediately recognized from memory, the agent needs to gather more context. This is where Retrieval-Augmented Generation (RAG) comes in. RAG provides the LLM with relevant reference material from an external knowledge base. For this pipeline, I'm using ChromaDB as the vector store.
For example, a generic LLM might know what a ‘CrashLoopBackOff’ is. But with RAG, we can provide it with our internal documentation, informing it that for our specific auth-service, a common cause is a misconfigured database connection—something only found in our private docs.
The RAG process involves:
- Ingesting Data: Relevant data sources like infrastructure knowledge graphs, code repositories, documentation, and communication channels are ingested. Given that an estimated two-thirds of outages are due to configuration and human errors, recent information from Git and Slack is particularly valuable.
- Chunking and Embedding: The source data is broken into chunks and converted into numerical representations (embeddings) using an embedding model.
- Storing: These embeddings are stored in a vector store (ChromaDB) for efficient semantic search.
- Retrieving: When an alert comes in, its summary and details are used to query the vector store, which returns the most relevant documents.
To test the stand alone RAG interactively on your own documents Run orchestration_agent/tools/rag_search/interactive.py
Uncovering Nuance with Deep Research¶
The deep research tool acts as an intelligent research assistant, capable of synthesizing information from multiple sources across the web. This is invaluable for:
- Error Investigation: Looking up obscure error codes or messages.
- Technology Stack Issues: Researching bugs or performance issues in open-source components.
- Third-Party Service Outages: Checking if a third-party service is experiencing a known outage.
- Security Vulnerabilities: Investigating potential security threats.
This deep research tool employs a multi-agent approach, with specialized agents for decision-making, query generation, and question-answering. This allows it to autonomously gather, process, and synthesize information, providing a comprehensive overview with citations and suggestions for follow-up questions. checkout orchestration_agent/tools/deep_research/interactive.py to run it as a stand alone deep researcher.
Reflection: The Key to Improved Performance¶
Interleaving reasoning and action (the ReAct framework) with moments of reflection has been shown to significantly improve performance. The more complex a task, the more potential failure points exist. After each step, our agent reflects on the generated response and the retrieved context. If the answer isn't satisfactory, the agent can iterate to refine its output.
def generate_final_answer(agent, input_schema, tool_response):
"""Generate a final answer based on the tool's output - this is the reflection step."""
# Temporarily switch to final answer schema
original_schema = agent.output_schema
agent.output_schema = FinalAnswerSchema
# Add tool response to memory for context
agent.memory.add_message("system", tool_response)
# Run agent again to synthesize final answer
final_answer_obj = agent.run(input_schema)
# Restore original schema
agent.output_schema = original_schema
return final_answer_obj
Bringing It All Together: LLM Reasoning and Prompt Assembly¶
With all the pieces in place, the agent assembles a prompt for the LLM. This prompt includes:
- The alert itself (the problem statement).
- The results from each step of the executed plan (logs, deployment info, metrics).
- Any additional context retrieved from the knowledge base.
The prompt instructs the LLM to analyze all this information and derive a root cause and a solution. The goal is to get a summarized, actionable response that explains what happened, where it happened, and how to fix it.
Conclusion: Augmenting, Not Replacing, Human Expertise¶
By combining AI-driven analysis with domain-specific knowledge and tools, an Agentic-SRE can dramatically reduce the complexity and time burden of incident management.
The key to success is maintaining a balance between automation and human judgment. While this AI assistant can significantly reduce cognitive load and accelerate troubleshooting, it remains a tool designed to augment, not replace, human expertise. By focusing on search space reduction, context enhancement, and pattern recognition, the assistant empowers SRE teams to make better, faster decisions.
As modern digital infrastructure continues to grow in complexity, tools like the Agentic-SRE will become increasingly vital for maintaining the reliability and performance that users expect. With Atomic-Agents framework they can be quickly integrated and modified. Through thoughtful implementation and continuous refinement, we can achieve new levels of operational excellence.
Let me know what you think?
- Can this agent help narrow the search space in SRE?
- Are you an SRE? how has new tooling changed your workflow?
- Where else could this type of orchestrator be applied?
- What other features would you like to see?
I'd love to hear your thoughts, comment or DM.
Donald McGillivray
mcgillivray.d@gmail.com