Introduction¶
The site Reliability Engineering (SRE) position was created out of necessity by Google to maintian its gigital infrastructure and is now a critical discipline across the technology industry. Today, SRE teams face mounting pressure to maintain system reliability while managing unprecedented scale and complexity. I believe The emergence of AI-driven assistants represents a paradigm shift in how we approach reliability engineering in all fields, promising to augment human expertise with intelligent automation, and its starting with SREs.
Agentic SRE systems autonomously reason about infrastructure problems, plan investigation strategies, and recommend solutions. Unlike traditional monitoring tools that simply alert on problems, these systems actively participate in the incident response process, reducing the cognitive load on human engineers and accelerating time to resolution.
The development of such systems requires a phased approach, similar to onboarding a new team member:
-
Learning Phase: The agent integrates with existing data sources, builds understanding of infrastructure and workflows, and provides immediate value through knowledge retrieval and context aggregation.
-
Reasoning Phase: The system develops sophisticated capabilities for root cause analysis and remediation suggestions, incorporating planning and advanced tool use while maintaining read-only access for safety.
-
Automation Phase: With deep system understanding, the agent begins automating routine procedures under human oversight—the ultimate goal of autonomous reliability engineering.
To see how I tackled developing such systems see: Agentic Reliability Engineering, and the code at github
Throughout this evolution, safety, reliability, and human oversight remain paramount. The challenge lies in building systems that provide genuine value to engineers while navigating the complexities of heterogeneous infrastructure, ensuring output accuracy, and maintaining robust safety protocols.
The Evolution of Site Reliability Engineering¶
Modern digital platforms are huge and wildly complex. Distributed architectures, microservices, cloud-native technologies, and continuous deployment cycles create intricate interdependencies that generate vast amounts of operational data. SRE teams have to minimize downtime, optimize critical metrics like Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR), to honor increasingly stringent Service Level Agreements (SLAs).
Traditional manual approaches and siloed tooling struggle to keep pace with this complexity. The industry has responded with AIOps platforms that leverage AI/ML to automate routine tasks, enhance observability through intelligent analysis of logs, metrics, and traces, and promise to detect anomalies, predict failures, and accelerate root cause analysis.
The Agentic SRE Landscape¶
The emergence of agentic SRE platforms represents a significant evolution beyond traditional AIOps. These systems don't just monitor and alert—they actively reason about problems, plan investigations, and recommend solutions. The following table showcases the current landscape of agentic SRE platforms and tools:
| Agentic SRE | Description | Good For | Open-Source | Website |
|---|---|---|---|---|
| Rootly | AI-native incident response platform integrating with Slack and Teams to automate on-call workflows and postmortems. | Incident response, Slack integration, postmortems. | ❌ | rootly.com |
| Nudgebee | AI-agentic assistants platform for modern SRE and Ops teams, offering specialized agents for cloud-native operations. | Kubernetes troubleshooting, cloud-native ops automation. | ❌ | nudgebee.com |
| Cleric | Autonomous AI SRE designed to manage, optimize, and heal software infrastructure, reducing alert fatigue. | Production issue diagnosis, infrastructure optimization. | ❌ | cleric.io |
| K8sGPT | AI-powered tool that diagnoses and fixes Kubernetes issues with intelligent insights and automated troubleshooting. | Kubernetes diagnostics, cluster management. | ✅ | k8sgpt.ai |
| Parity | AI SRE acting as the first line of defense for on-call engineers, particularly in Kubernetes environments. | Incident response, Kubernetes operations. | ❌ | tryparity.com |
| SRE.ai | AI-powered automation platform for Salesforce development teams, providing agents that deploy between environments, configure and execute workflows, and query for information with just a chat message. | Salesforce DevOps, CI/CD, merge conflict resolution, environment management. | ❌ | sre.ai |
| Agent SRE | Open-source framework enabling autonomous interaction with computers through an agent-computer interface. | Automating GUI tasks, AI agent development. | ✅ | GitHub |
| Beeps | An on-call platform tailored for Next.js developers, offering rapid incident resolution with integrations to GitHub, Vercel, Slack, and more. | Autonomous task execution, content creation.Incident response, Next.js applications, observability integration. | ❌ | beeps.dev |
| ControlFlow | Python framework for building agentic AI workflows, allowing structured task delegation to LLMs. | AI workflow orchestration, task automation. | ✅ | GitHub |
| RunWhen | Platform to build specialized SRE, Platform, and DevOps assistants leveraging a library of pre-built automation. | Alert response, ticket drafting, DevOps automation. | ❌ | runwhen.com |
| Wild Moose | AI-powered SRE copilot that automates root cause analysis and streamlines incident response. | Real-time incident analysis, observability integration. | ❌ | wildmoose.ai |
| Kura | Intelligent DevOps copilot that integrates directly with AWS to answer questions, generate code, and assist with everyday DevOps tasks. | AWS infrastructure management, incident response, resource provisioning. | ❌ | usekura.com |
Magnitude of the task¶
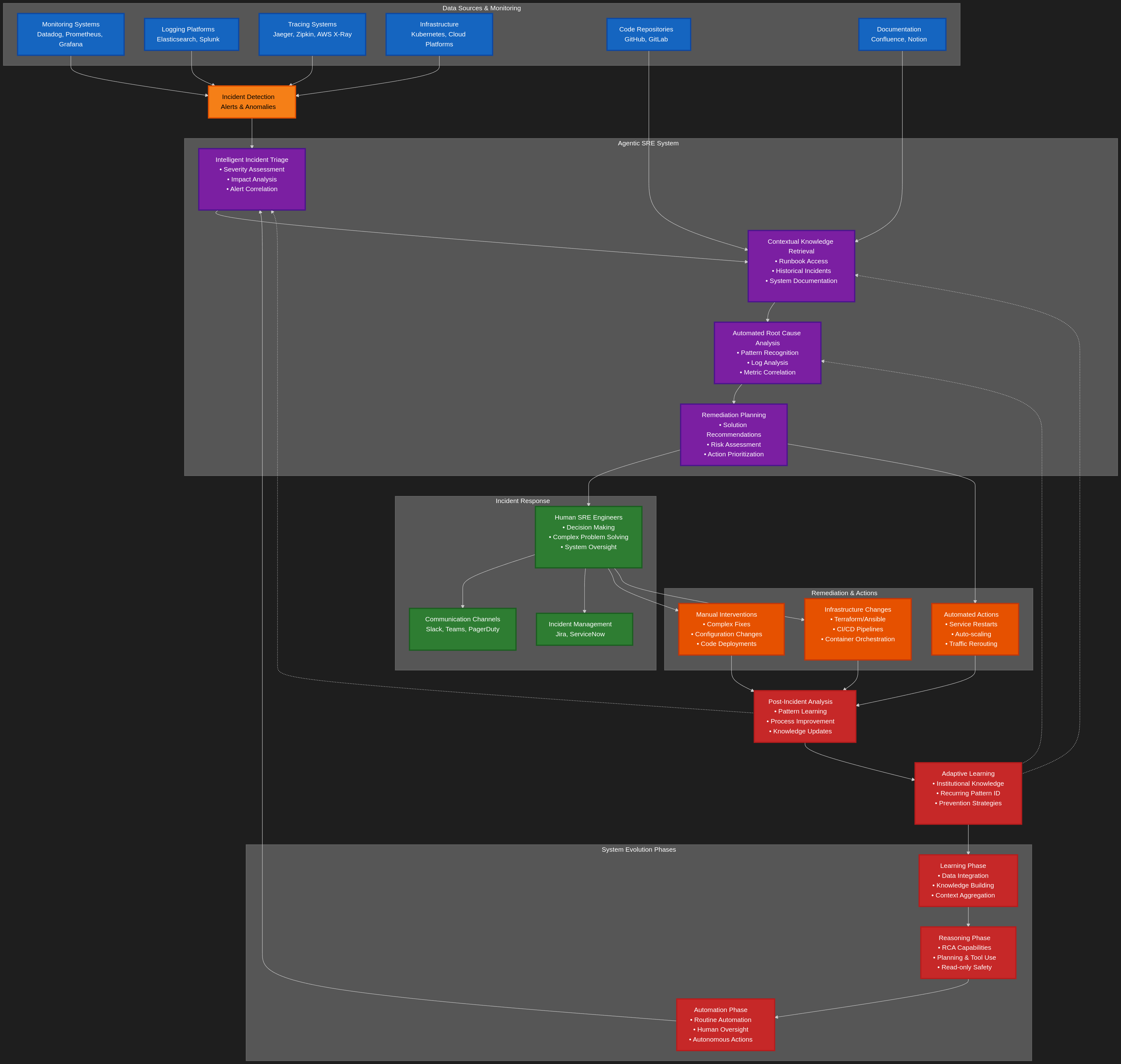 integrating AI SRE within a heterogeneous landscape of tools and data sources is challenging. Sources include:
- monitoring and observability platforms (e.g., Datadog, Prometheus, Grafana),
- code repositories (GitHub),
- documentation platforms (Confluence, Notion),
- communication channels (Slack),
- incident management systems (Jira, PagerDuty, ServiceNow),
- databases, and custom internal tools.
Each enterprise will be different and will bring their own systems, procedures, and datasets.
integrating AI SRE within a heterogeneous landscape of tools and data sources is challenging. Sources include:
- monitoring and observability platforms (e.g., Datadog, Prometheus, Grafana),
- code repositories (GitHub),
- documentation platforms (Confluence, Notion),
- communication channels (Slack),
- incident management systems (Jira, PagerDuty, ServiceNow),
- databases, and custom internal tools.
Each enterprise will be different and will bring their own systems, procedures, and datasets.
Distributed infrastructure like Kubernetes and Kafka adds additional layers of complexity:
- clusters may span multiple clouds and on‑prem environments,
- workloads are highly ephemeral,
- and autoscaling or self‑healing actions can erase the evidence an investigator needs.
SREs must also cope with cascading failures triggered by resource‑starved nodes, stuck rollouts, or misconfigured network policies that can silently break. The AI agent must be able to speak to the Kubernetes API or Kafka topics fluently:
- watching events and topics, querying etcd‑backed states,
- and correlating pod restarts, image hashes, and recent kubectl apply operations with upstream alerts.
Complicating SRE design, each enterprise will bring its own cluster topologies, admission‑controller policies, and GitOps workflows, so these bespoke attributes need to be imported and integrated in the base agent. The prompts, logic, and pipelines should therefore generalize not only across tool stacks but also across wildly different Kubernetes footprints, enabling rapid RCA and remediation in any customer environment.
Core Capabilities of Agentic SRE Systems¶
Successful agentic SRE systems share several fundamental capabilities that distinguish them from traditional monitoring and alerting tools:
Intelligent Incident Triage¶
Rather than simply forwarding alerts, agentic systems can analyze incoming incidents, assess severity and impact, and prioritize response efforts. They can correlate multiple alerts to identify potential cascading failures and route incidents to the most appropriate team members based on expertise and availability.
Contextual Knowledge Retrieval¶
These systems excel at gathering relevant context from diverse sources—runbooks, previous incident reports, system documentation, recent deployments, and real-time metrics. This capability dramatically reduces the time engineers spend searching for relevant information during high-pressure incidents.
Automated Root Cause Analysis¶
By analyzing patterns across logs, metrics, traces, and system events, agentic SRE systems can identify potential root causes and present them in order of likelihood. This doesn't replace human judgment but significantly narrows the investigation scope.
Adaptive Learning¶
The most sophisticated systems learn from each incident, building institutional knowledge that improves future responses. They can identify recurring patterns, suggest process improvements, and even recommend infrastructure changes to prevent similar issues.
Common Tools and Technologies¶
The agentic SRE ecosystem leverages several categories of tools and technologies:
Observability Platforms¶
- Monitoring Systems: Datadog, New Relic, Prometheus, Grafana
- Logging Platforms: Elasticsearch, Splunk, Fluentd
- Tracing Systems: Jaeger, Zipkin, AWS X-Ray
- APM Tools: AppDynamics, Dynatrace
Incident Management¶
- Alerting: PagerDuty, Opsgenie, VictorOps
- Communication: Slack, Microsoft Teams, dedicated incident channels
- Ticketing: Jira, ServiceNow, Linear
Knowledge Management¶
- Documentation: Confluence, Notion, GitBook
- Runbooks: Automated playbooks, decision trees
- Post-mortem Systems: Incident retrospective tools
Infrastructure as Code¶
- Configuration Management: Ansible, Terraform, Pulumi
- Container Orchestration: Kubernetes, Docker Swarm
- CI/CD Pipelines: Jenkins, GitLab CI, GitHub Actions
For a detailed technical implementation of an agentic SRE system, see Agentic Reliability Engineering.
Future Outlook¶
Autonomous Remediation¶
While current systems focus on diagnosis and recommendation, the next generation will increasingly handle automated remediation for well-understood, low-risk scenarios. This includes automatic scaling, service restarts, configuration rollbacks, and traffic rerouting.
Predictive Reliability¶
Advanced systems will move beyond reactive incident response to predictive reliability engineering. By analyzing trends in system behavior, deployment patterns, and external factors, these systems will identify potential issues before they impact users.
Cross-System Intelligence¶
Future agentic SRE platforms will operate across organizational boundaries, sharing anonymized insights about common failure patterns, effective remediation strategies, and emerging threats across the broader technology ecosystem.
Human-AI Collaboration¶
For the time being, most implementations will focus on augmenting human expertise rather than replacing it. This includes intelligent workload distribution, context-aware assistance, and adaptive interfaces that match individual engineer preferences and expertise levels.
Regulatory and Compliance Integration¶
As systems become more autonomous, they'll need to incorporate regulatory requirements, compliance frameworks, and audit trails directly into their decision-making processes.
Challenges and Considerations¶
Trust and Reliability¶
Building systems that engineers trust requires transparent decision-making, consistent performance, and graceful failure modes. The cost of false positives or incorrect remediation can be severe.
Integration Complexity¶
Modern infrastructure involves dozens of tools and platforms. Agentic systems must navigate this complexity while maintaining performance and reliability.
Skills Evolution¶
As these systems become more capable, SRE roles will evolve. Engineers will need to develop new skills in AI system management, prompt engineering, and human-AI collaboration.
Ethical Considerations¶
Autonomous systems making decisions about critical infrastructure raise important questions about accountability, bias, and the appropriate level of human oversight.
Conclusion¶
system reliability engineering is in flux with new procedures and protocols. Combining AI capabilities with domain expertise, these systems promise to make reliability engineering more effective, efficient, and scalable. SRE's are where this is being applied to first. Success will requires careful attention to trust, safety, and the evolving role of human expertise in an increasingly automated world.
The field is rapidly evolving, with new platforms and capabilities emerging regularly. Organizations considering agentic SRE implementations should focus on clear use cases, robust evaluation frameworks, and gradual capability expansion while maintaining strong human oversight and safety protocols.