Pydantic-AI Investment Research System¶
This document details a multi-agent investment research system designed to autonomously gather and analyze financial data. The system performs comprehensive financial analysis and generates actionable investment insights. Its adaptive architecture, featuring dynamic plan adjustment and intelligent memory management, allows it to evolve its research strategy based on real-time findings.
Overview¶
This investment research system leverages a multi-agent architecture built on Pydantic-AI to provide comprehensive, adaptive financial analysis. The system combines autonomous AI agents with specialized tools to gather data from multiple sources, perform calculations, and generate actionable investment insights. The system uses adaptive memory management and dynamic plan adjustment, to evolve its research strategy based on findings.
The Agents¶
The system employs specialized agents built using pydantic-ai that handle different aspects of the research process.
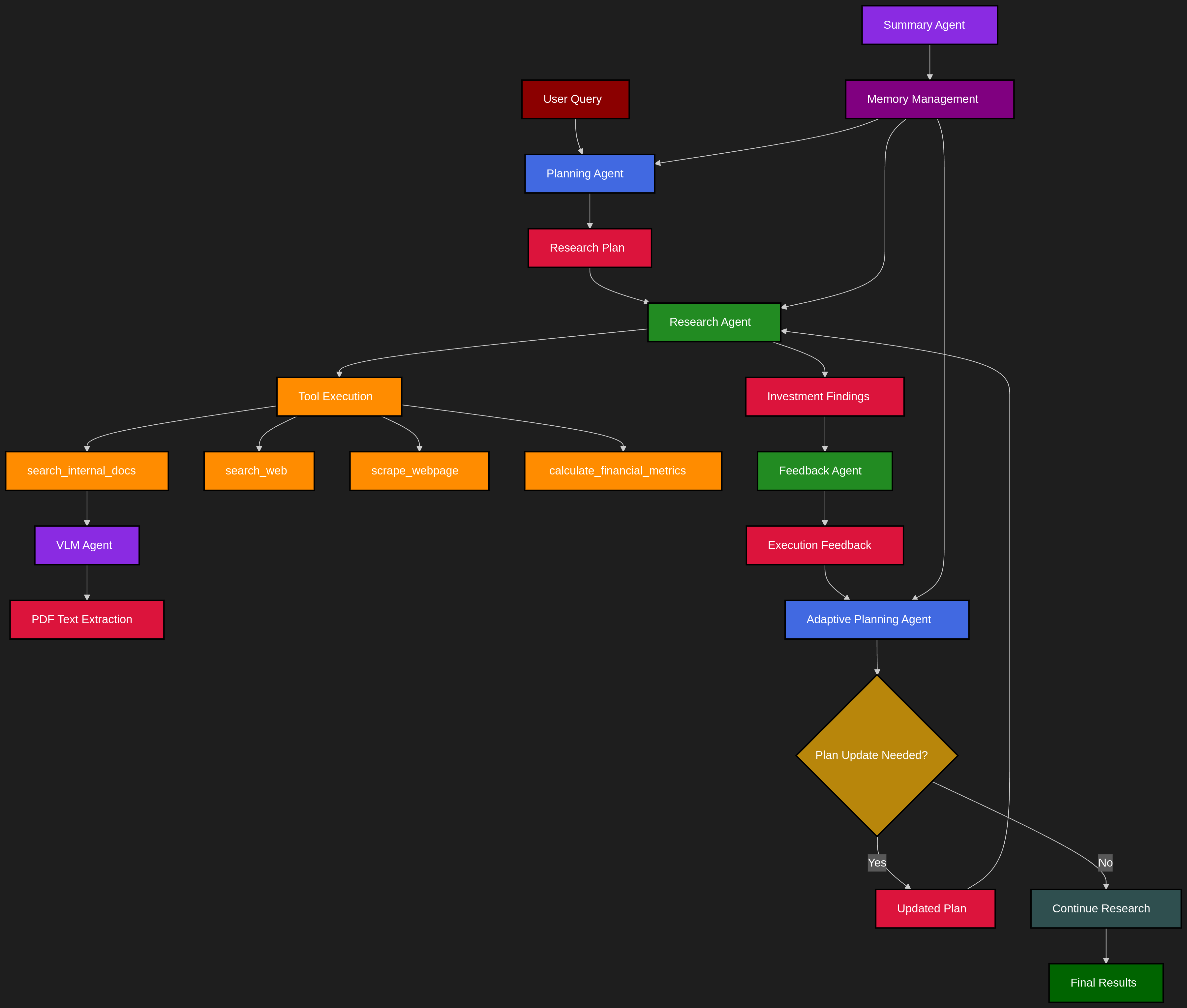 Figure 1: Agent topology. Blue - planning agents, Green - Research agents, Purple - Specilized agents. Red - agent output, Yellow - Tools
Figure 1: Agent topology. Blue - planning agents, Green - Research agents, Purple - Specilized agents. Red - agent output, Yellow - Tools
Architecture¶
The project follows an atomic, modular architecture with clear separation of concerns to help me focus on composability:
agents/
├── dependencies.py # Type-safe shared context and resources
├── memory_processors.py # Advanced memory management for conversations
├── planning_agent.py # Investment research planning and adaptation
└── research_agent.py # Research execution with tool orchestration
tools/
├── calculator.py # Financial metrics and ratio calculations
├── pdf_extractor.py # Hybrid PDF extraction (PyMuPDF + VLM)
├── vector_search.py # ChromaDB document search with caching
├── web_scraper.py # BeautifulSoup content extraction
└── web_search.py # Tavily API integration (not SearxNG)
models/
└── schemas.py # Pydantic data models for type safety
streamlit_app.py # Web interface with multiple research modes
main.py # CLI entry point and core workflows
config.py # OpenRouter/OpenAI configuration
logfire_config.py # Observability and monitoring setup
Core Agents¶
Planning Agents¶
| Agent | Purpose | Input | Output | Memory Strategy |
|---|---|---|---|---|
| planning_agent | Creates initial 2-4 step research plans following investment methodology | User query + context | ResearchPlan with logical steps, reasoning, and priorities |
Uses adaptive_memory_processor for conversation management |
| adaptive_planning_agent | Evaluates execution feedback and dynamically adjusts plans | PlanUpdateRequest with feedback and remaining steps |
PlanUpdateResponse indicating plan updates needed |
Minimal context strategy - keeps only system prompt + last 2 successful decisions |
Research Agents¶
| Agent | Purpose | Input | Output | Memory Strategy |
|---|---|---|---|---|
| research_agent | Executes research plans using available tools | Query + plan + ResearchDependencies |
InvestmentFindings with summary, insights, metrics, risks, recommendation |
Uses filter_research_responses to preserve valuable content |
| feedback_agent | Evaluates research quality after each step | Step description + findings + expectations | ExecutionFeedback with quality scores, gaps, confidence |
Stateless evaluation |
Specialized Agents¶
| Agent | Purpose | Usage | Key Features |
|---|---|---|---|
| summary_agent | Condenses conversation history while preserving key findings | Activated when conversations exceed 6 messages | Summarizes older messages while keeping recent 3 intact |
| vlm_agent | Vision-Language Model for PDF text extraction | Fallback when PyMuPDF quality < threshold | Processes PDF pages as images for complex layouts |
Available Tools¶
The research_agent autonomously decides when and how to use these tools:
| Tool | Function | Features | Implementation |
|---|---|---|---|
| search_internal_docs | Searches ChromaDB vector database | Query enhancement, result caching (5min TTL), relevance scoring | ChromaDB with embeddings |
| search_web | Current market news and analysis | Privacy-focused search, multiple categories | Tavily API (not SearxNG) |
| scrape_webpage | Extract content from web pages | Article/table/full content modes | aiohttp + BeautifulSoup4 |
| calculate_financial_metrics | Compute financial ratios | P/E, debt ratios, ROE, margins, etc. | LLM-based parsing and calculation |
Memory Management System¶
The adaptive_memory_processor implements sophisticated conversation management:
- Short conversations (≤6 messages): Keep all with validation
- Medium conversations (7-12 messages): Filter responses, keep 8 recent
- Long conversations (>12 messages): Aggressive filtering, keep 6 essential
Key features: - Tool call sequence integrity: Maintains proper tool call → response pairs - Research keyword preservation: Keeps messages with "analysis", "findings", "recommendation", etc. - Context preservation: Always maintains system prompts - Session-level caching: 5-minute TTL for vector search results
How It All Connects: The Workflow¶
The system operates to transforms a user's investment query into comprehensive analysis. The process begins when the user submits their question (either through either the CLI or the Streamlit web app). This query, along with any relevant context about investment goals or constraints, is processed by the planning agent, which analyzes the request and formulates a logical research strategy consisting of 2-4 steps. That is followed by orchestration of research consisting of a loop of data gathering and analysis, culminating in a report, final recommendation, and its confidence.
Upon creation of the initial plan, the research agent takes over execution, working through each planned step sequentially. For each step, the agent autonomously determines which tools are most appropriate for gathering the required information. It might start by searching the internal vector database for relevant SEC filings and earnings reports, then expand to web searches for current market sentiment and news, and finally perform financial calculations on the gathered data. (It will soon be able to use API as well) Throughout this process, the agent maintains awareness of what information has already been collected and what gaps remain to be filled.
The adaptive workflow mode adds an additional layer of intelligence through continuous evaluation and adjustment of the plan. After each research step completes, the feedback agent assesses the quality and completeness of the findings, generating structured feedback that includes confidence scores, identified data gaps, and unexpected discoveries. This feedback is then passed to the adaptive planning agent, which decides whether the original plan needs modification. It updates the state through memory. If significant gaps are identified or valuable unexpected information is discovered, the planning agent can insert new steps, reorder priorities, or remove redundant tasks. This creates an iterative loop where the system learns and adapts as it progresses, much like a human analyst who adjusts their approach based on initial findings.
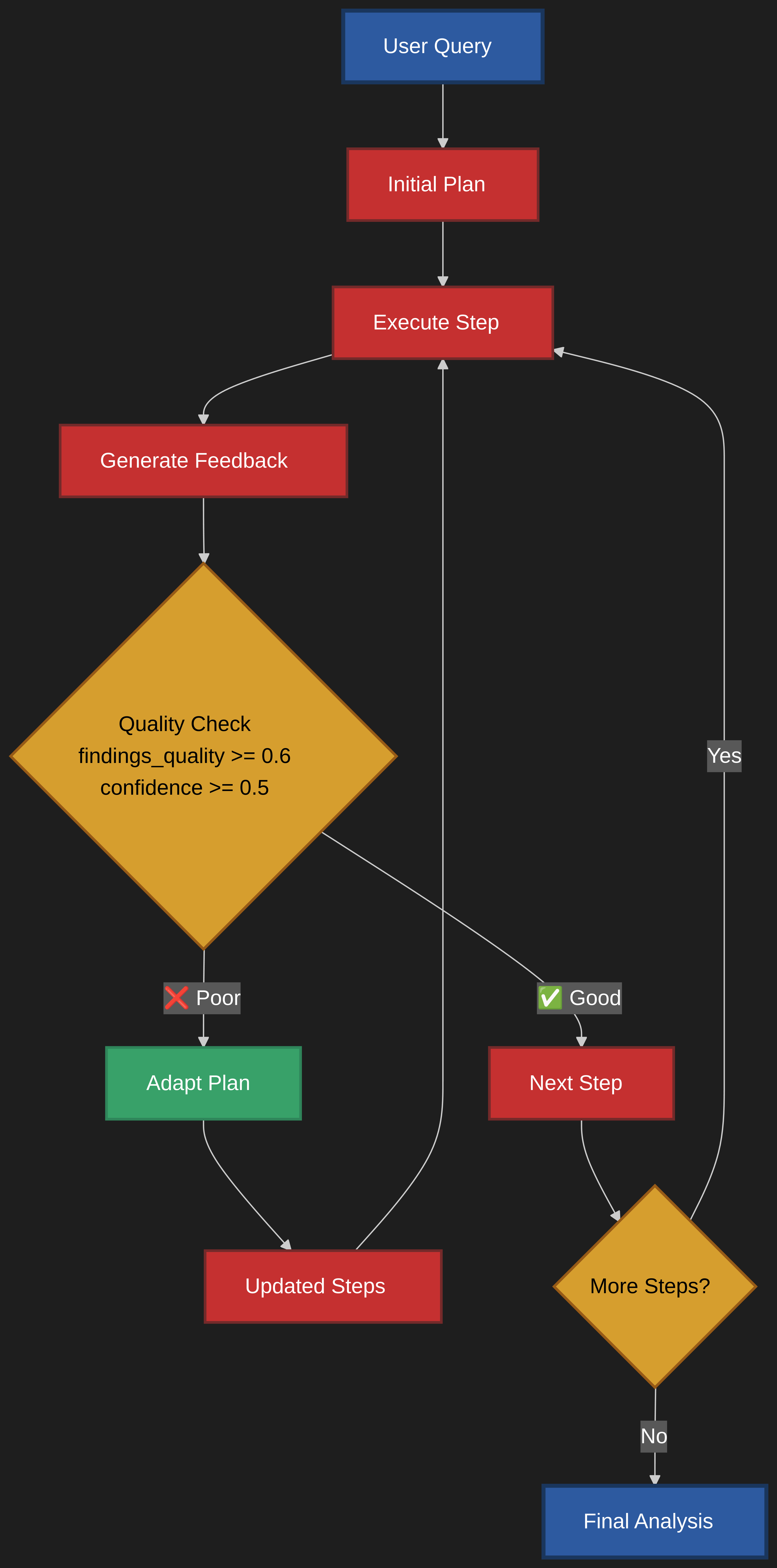 Blue - Start/End, Red - Core Process, Orange - Decisions, Green - Adaptation, Purple - Execution.
Blue - Start/End, Red - Core Process, Orange - Decisions, Green - Adaptation, Purple - Execution.
Throughout the entire workflow, the memory management system ensures efficient operation by intelligently filtering and summarizing conversation history to prevent token explosion while preserving essential context. The system maintains multiple types of memory: permanent storage in the vector database for documents, session-level caching for search results, and adaptive conversation memory that adjusts its retention strategy based on conversation length. All findings are continuously aggregated and structured according to Pydantic schemas, ensuring type safety and consistency. The workflow concludes when either all planned steps are completed or the confidence threshold is met, at which point the system generates a final InvestmentAnalysis containing a comprehensive summary, key insights, risk factors, opportunities, and a clear investment recommendation with supporting rationale.
Workflow Modes¶
The system supports multiple research modes through the Streamlit interface:
- Simple Chat: Basic Q&A without tools
- RAG Only: Vector database search only
- Deep Research: Web search + analysis
- Full Planning: Complete workflow with planning agent
- Adaptive Memory: Full workflow with dynamic plan adaptation
Running the System¶
Prerequisites¶
# Install dependencies
poetry install
# Set environment variables
export OPENROUTER_API_KEY="your-openrouter-api-key"
export TAVILY_API_KEY="your-tavily-api-key" # For web search
# Optional: Logfire for observability
export LOGFIRE_TOKEN="your-logfire-token"
Usage Options¶
-
Command Line Interface:
python main.py -
Streamlit Web Interface (recommended):
streamlit run streamlit_app.py -
Programmatic Usage:
from main import adaptive_research_investment analysis = await adaptive_research_investment( query="Should I invest in Apple?", context="Conservative investor, 5-year horizon", max_adaptations=3 )
Configuration¶
- LLM Provider: Configured for OpenRouter (supports OpenAI-compatible APIs)
- Vector Database: ChromaDB with local persistence at
./investment_chroma_db/ - Knowledge Base: Pre-loaded documents in
./knowledge_base/ - Default Model: GPT-4 variants via OpenRouter
The system's modular design allows easy extension with new agents, tools, or data sources while maintaining clear boundaries between components.
Conclusion: Augmenting Human Expertise¶
This Pydantic-AI based system offers a powerful and flexible framework for building sophisticated, AI-driven investment research applications. Its emphasis on modularity, composability, natural tool use, and adaptive planning.
Before embarking on any endeavour research must be conducted. By automating the time-consuming work of data gathering and analysis, the agent significantly reduces the search space, illuminating a path for humans. It serves as a powerful tool to enhance context, recognize patterns, and ultimately empower us to make better, faster decisions. The complexity of financial markets are growing, agentic systems like this one are vital for maintaining a competitive edge.