Intelligence is what one can do with a little bit of information. Stupidity is what one can't do with a lot of information. Today's LLMs and AI fall into the latter category; however, we can push them in the direction of the former by providing them with the context they require to make decisions. The most effective way of doing that is with Retrieval-Augmented Generation (RAG).[1]
 The latest buzzword is context engineering. Gone is the way of prompt engineering, where the user had to think of ways to best elicit the desired output from the model. We now know enough to provide the right phrasing in the system prompt and then programmatically retrieve the right context needed for the task to fill in the rest. For example: documentation, date and time, few-shot examples, available tools, etc. RAG is the obvious way to search for relevant information, but ill note it can also be done using agents.
The latest buzzword is context engineering. Gone is the way of prompt engineering, where the user had to think of ways to best elicit the desired output from the model. We now know enough to provide the right phrasing in the system prompt and then programmatically retrieve the right context needed for the task to fill in the rest. For example: documentation, date and time, few-shot examples, available tools, etc. RAG is the obvious way to search for relevant information, but ill note it can also be done using agents.
RAG dynamically updates the model's context with relevant information by connecting to data sources and selecting the entries matching the search. RAG is good for real-time data access, combating hallucinations, combating stale knowledge, applying rules or guardrails, and overcoming the model's lack of memory.
The RAG Workflow¶
There's a meme that RAG is dead. Proponents invoke the argument that RAG might not be needed in the future when model context length grows significantly or through "agentic RAG," where an agent searches for the relevant context. However, I believe it will stick around because it can be used with small, fast LLMs or LLMs running on restricted hardware.[2] While context lengths are growing rapidly, in some applications, the data is increasing even faster. Possibly, the volume of data will always be more than the context window. And, of course, RAG is key for context engineering. This is an optimization problem where you want to give the model the maximum relevant context without overfitting, causing inadvertent steering from irrelevant data, or causing "context rot."
RAG is only useful if your data has value. If the LLM alone can provide the answer, then you don't need RAG, and your dataset is more or less worthless. You've been scooped. I am being jocose, because context engineering with your data can prime the model to get it in the right latent space and frame it to provide a valuable answer. But it is here that we see the trade-off between prompt engineering and context engineering at its clearest. If the model can be prompted easily to return a correct solution, that's all that's needed. If a bit of extra context is warranted, then RAG can be useful, given other considerations such as latency and compute.
RAG can be as simple as a few lines of code and can scale to the enterprise level. I've deployed a few RAG systems and these are my learnings. I'll walk you through something that can immediately provide value on your chatbot, website search, blog, business resources, or other applications.
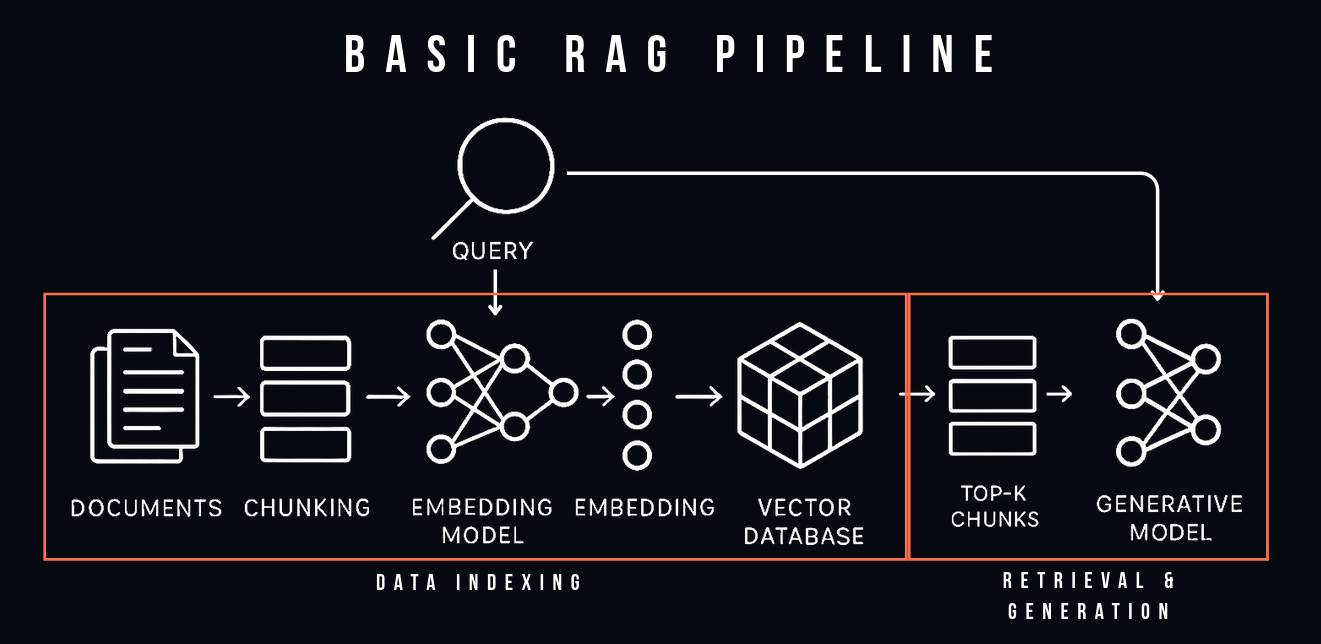 RAG is a trade-off: it improves query-time performance at the cost of write-time performance. It can be divided into data indexing (offline processing) and retrieval and generation (online processing). Since we can pre-process the dataset offline, we can balance accuracy and speed and can return responses in the fashion suitable for the application. This is a continuation of the decoupling trend of separating read/write and storage/compute operations of modern distributed systems and ensures the system is easily adaptable.
RAG is a trade-off: it improves query-time performance at the cost of write-time performance. It can be divided into data indexing (offline processing) and retrieval and generation (online processing). Since we can pre-process the dataset offline, we can balance accuracy and speed and can return responses in the fashion suitable for the application. This is a continuation of the decoupling trend of separating read/write and storage/compute operations of modern distributed systems and ensures the system is easily adaptable.
It is further split into five main components:
Offline:
-
Preprocessing the documents (cleaning and chunking the data)
-
Embedding the chunks into vectors using an embedding model
-
Vector database storage
Online:
-
Retrieval
-
Generation
Part 1: Indexing (Offline)¶
Ingestion of Documents¶
In machine learning, pre-processing our data has always been, I would argue from the data science side, the biggest pain and time and accuracy bottleneck. The law, garbage in, garbage out, always applies. The quality of RAG's responses depends on how the data is stored and pre-processed. This requires looking at the data, converting it all to unified plain text, and removing images, artifacts, and other unwanted data. PDFs are the worst file format; on conversion, they often have useless headers and footers. It is recommended to use an OCR tool, like Tesseract,[7] to extract info from images, diagrams, and charts and to extract tables. Specialized PDF parsing tools like NeMo Retriever can significantly improve extraction accuracy and efficiency compared to general-purpose approaches.[11] These tools use multi-stage processing with dedicated models for different content types, resulting in better retrieval performance. On the governance side, the data needs to be scrubbed of unwanted information, especially personally identifiable information (PII), to be compliant with the standards you are working within (e.g., GDPR, HIPAA...). It is here that security starts, and access control filtering and audit trails can be implemented.
Chunking¶
Having just looked at the data to clean it, it is easier to envision how one can split it up into chunks. How you chunk depends on how you intend to retrieve it later. The size of the chunk is a balance between small, diverse, and computationally heavy embeddings versus large, self-contained but superfluous data with lightweight embeddings. If the data is code, you can use a tool like tree-sitter to chunk by methods,[8] functions, or classes. If it's documents, you can chunk by pages, paragraphs, sentences, or use a recursive strategy. Q&A pairs should be split together. The most thoughtless chunking strategy is a fixed length of a number of words. This isn't ideal, as it often breaks sentences or ideas in half. The goal is for each chunk to be a complete semantic unit, not a random fragment that gets split mid-concept.[10] If you must use fixed length, overlap chunks so context between them is not lost, and spend some time optimizing the responses. The chunk size must not exceed the context length of the generative or the embedding model. There are documented best practices depending on the data—like for Chinese, math, images, etc.—and a quick search can save a lot of re-engineering.
Embedding and Storage¶
With chunks in hand, they can be passed through an embedding model. It converts the important properties of the original data into a vector. A model like nvidia/Llama-3.2-nv-embedqa-1b-v2 is fast, efficient,[9] has a long context window, supports multiple languages, and scores well on retrieval tasks. But there are lots of off-the-shelf models to choose from, specific to the types of input data, and it's not hard to fine-tune one for your own use case to squeeze that extra bit of accuracy out. When selecting an embedding model, it's also useful to consult the MTEB benchmark,[12] which evaluates embeddings across a wide range of retrieval and semantic tasks, helping guide the choice for your application.
The vectors are stored in a vector database along with the plain text chunks and any metadata you want to include. The vector database does two things: it stores the data and it performs vector search. The former is easy; the latter is hard and where the magic is. Vector search is a nearest neighbor search problem: given a query, find the k-nearest neighbors to it. It does this by computing similarity scores (e.g cosine similarity) between the vectors and then ranks all vectors based on their scores, returning the k vectors with the highest scores. For large datasets, the Approximate Nearest Neighbor (ANN) algorithm is used for speed. You can use a variety of vector databases, from open-source options like pgvector, Qdrant, and Chroma to managed enterprise solutions. Metadata (such as author, page number, date, section, etc.) is valuable to include with the chunks. The more detailed the index, the better the accuracy; however, it will be slower to build (I am increasingly running into cases were metadata was greater than the actual data it was discribing, and I suspect this will continue).
Part 2: Retrieval and Generation (Online)¶
Retrieval¶
With the data cleaned, chunked, embedded, and neatly stored away, we can get to the exciting part: retrieval. While vector search is powerful for finding semantically similar information, we can get a lot smarter. A more robust approach is a hybrid search, which combines the best of both worlds: dense retrieval (our vector search) for understanding meaning, and sparse retrieval (keyword-based search like BM25 or Elasticsearch) for pinpointing exact lexical matches. While dense retrieval is powerful, for many use cases, fast and cheap sparse retrieval is all that's needed. This dual-pronged attack ensures we get results that are not only conceptually related but also contain the specific terms we are looking for.
To merge the results of dense and sparse retrieval, we can use Reciprocal Rank Fusion (RRF) to combine the ranked lists from both searches into a single, more relevant list.[6] For large datasets, the initial retrieval uses ANN—a fast and relatively cheap first pass—to fetch a broad set of candidate documents. After this, reranking should be done. A more sophisticated and computationally expensive reranking model can perform a deeper analysis on this smaller subset, reordering them to place the absolute best matches at the top. This two-stage process is a classic trade-off, balancing speed and cost with precision and ensuring the model gets the most potent context to work with.
Prompting and Generation¶
Despite the focus on context engineering, the prompt hasn't gone away. While a simple prompt will work, thought needs to be put into it. The prompt should be optimized, and it's a good thing we looked at our data because it rests on the underlying data type (e.g., code, question/answers, law documents). It is based on a number of factors: the generator model being used, the number of documents retrieved, the specific format of the input/output, etc. It is important that the prompt encourages the model to say "I don't know," otherwise you will get hallucinations. For chatbot RAG applications, a separate model can be used for query rewriting so that context from previous turns of the conversation can be included if needed.
RAG_TEMPLATE = """
#CONTEXT:
{context}
QUERY:
{query}
Use the provided context to answer the provided query. Only use the provided
context to answer the query. If you do not know the answer, or it's not contained
in the provided context respond with “I don't know”
"""
Most people consider the LLM to be the most critical part of an AI system, but it's not in RAG. Most of the heavy lifting should have been done at this point. Often, all that is needed is a model just smart enough to assemble the answer from the query and the retrieved context. The choice of generator model is based on the use case, domain, context window, and cost.
Evaluation and Advanced Techniques¶
Testing and Evaluation¶
Once the system is working, it’s critical to test it thoroughly. Challenge it with edge cases, such as queries about data not present in the corpus or with deliberately misleading metadata. Build a “gold standard” dataset of query-document pairs and measure metrics like Context Precision (are the retrieved documents relevant?) and Context Recall (did the system retrieve all relevant documents?). For small datasets, this can be done manually. For larger ones, you can automate evaluation with an LLM-as-a-judge.[3] In this approach, a separate model reviews the retrieval and rates its relevance. benchmarks like MTEB for scoring embeddings or Tools like DSPy can also be used here to optimize prompts, structure evaluations, and experiment with retrieval strategies in a systematic way.[4,5]
Scaling and Advanced RAG¶
Once your PoC is validated, you can scale the system to be as complex as your use case requires. This could involve sharding and replicating your database for performance and reliability. You can also focus on several areas of optimization:
-
Retrieval Optimization: Fine-tuning the search process for better accuracy and speed.
-
Model Optimization: Using more efficient models, which can lead to significant cost savings.
-
Prompt Optimization: Refining the prompts sent to the LLM for more consistent and accurate generation.
Beyond a basic setup, the world of RAG offers advanced techniques for different data types. These include multimodal RAG for images, tabular RAG for structured data, and my personal favorite, graph RAG, which is excellent for retrieving information based on its relationships to other data points.
Final Thoughts¶
When Not to Use RAG¶
Maybe it should have been mentioned at the beginning, but RAG should not be used in all scenarios. It should be used for Q&A, not to make a model smarter. If the model already knows the answer, you don't need RAG. It's also not great for creative writing, as semantic meaning doesn't work the same way for poetry. Don't use it if extremely low latency is needed. It can be faster than providing all the data directly to an LLM, but it does add some latency. It's not good for volatile (e.g., stock tickers) or conflicting data. If the dataset is small enough that it can easily fit in the context window (before context rot) or the use case is limited, it could be overkill. RAG systems do need to be maintained, monitored, and adjusted.
Conclusion¶
So what have we done? We traded write-time performance (indexing, which can be done offline) for query-time performance. In so doing, we reduced hallucinations, provided real-time data access, reduced out-of-date and stale knowledge, and gave the model memory. Search is a key workflow in modern AI systems, and RAG is the workhorse that provides semantic search and better results for your queries.
References¶
-
Huyen, C. (2024). AI Engineering: Building Applications with Foundation Models. Chip Huyen.
-
Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." arXiv preprint arXiv:2005.11401.
-
Zheng, L., et al. (2023). "Judging LLM-as-a-judge with MT-Bench and Chatbot Arena." arXiv preprint arXiv:2306.05685.
-
Muennighoff, N., et al. (2022). "MTEB: Massive Text Embedding Benchmark." arXiv preprint arXiv:2210.07316.
-
Khattab, O., et al. (2023). "DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines." arXiv preprint arXiv:2310.03714.
-
Cormack, G. V., Clarke, C. L., & Buettcher, S. (2009). "Reciprocal Rank Fusion for Extreme Scale Search." In Proceedings of the 18th international conference on World wide web.
-
Tesseract OCR. (n.d.). GitHub Repository. Retrieved from
https://github.com/tesseract-ocr/tesseract -
Tree-sitter. (n.d.). Official Website. Retrieved from
https://tree-sitter.github.io/tree-sitter/ -
NVIDIA NIM. (2024).
Llama-3.2-nv-embedqa-1b-v2Model Card. Hugging Face. Retrieved fromhttps://huggingface.co/nvidia/Llama-3.2-nv-embedqa-1b-v2 -
Li, Y. K., Wornell, G. W., & Win, M. Z. (2024). "Information-Theoretic Limits on Compression of Semantic Information." arXiv preprint arXiv:2407.03969.
-
NVIDIA Developer Blog. (2024). "Approaches to PDF Data Extraction for Information Retrieval." Retrieved from
https://developer.nvidia.com/blog/approaches-to-pdf-data-extraction-for-information-retrieval/ -
Muennighoff, N., et al. (2022). "MTEB: Massive Text Embedding Benchmark." Hugging Face Leaderboard. Retrieved from
https://huggingface.co/spaces/mteb/leaderboard